🤖 Under Review
UniIntervene
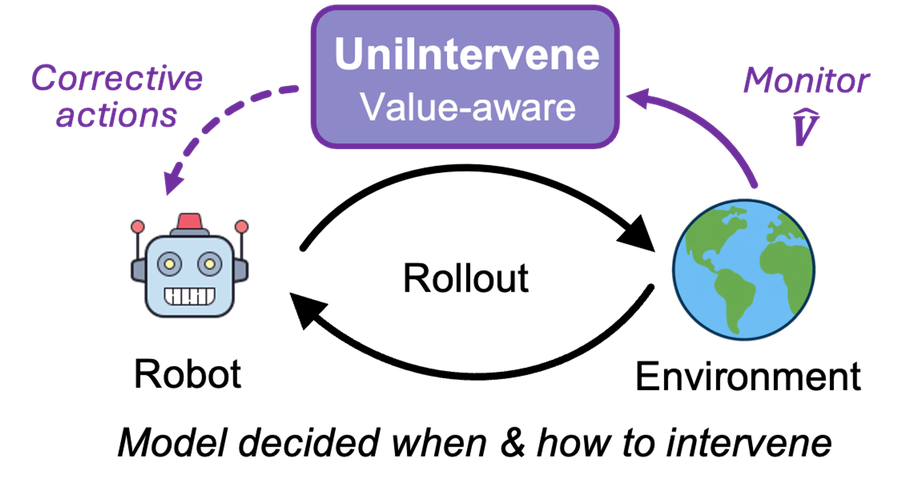
Agentic Intervention for Efficient Real-World Reinforcement Learning
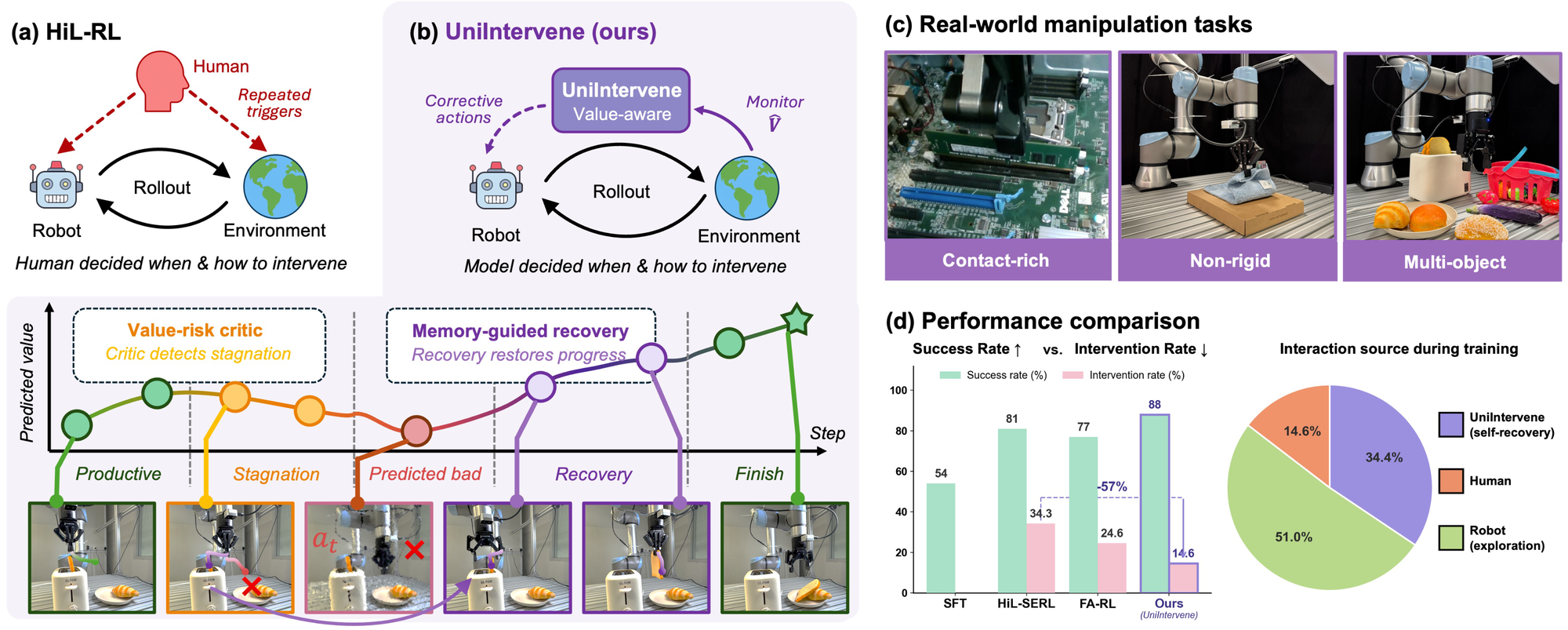
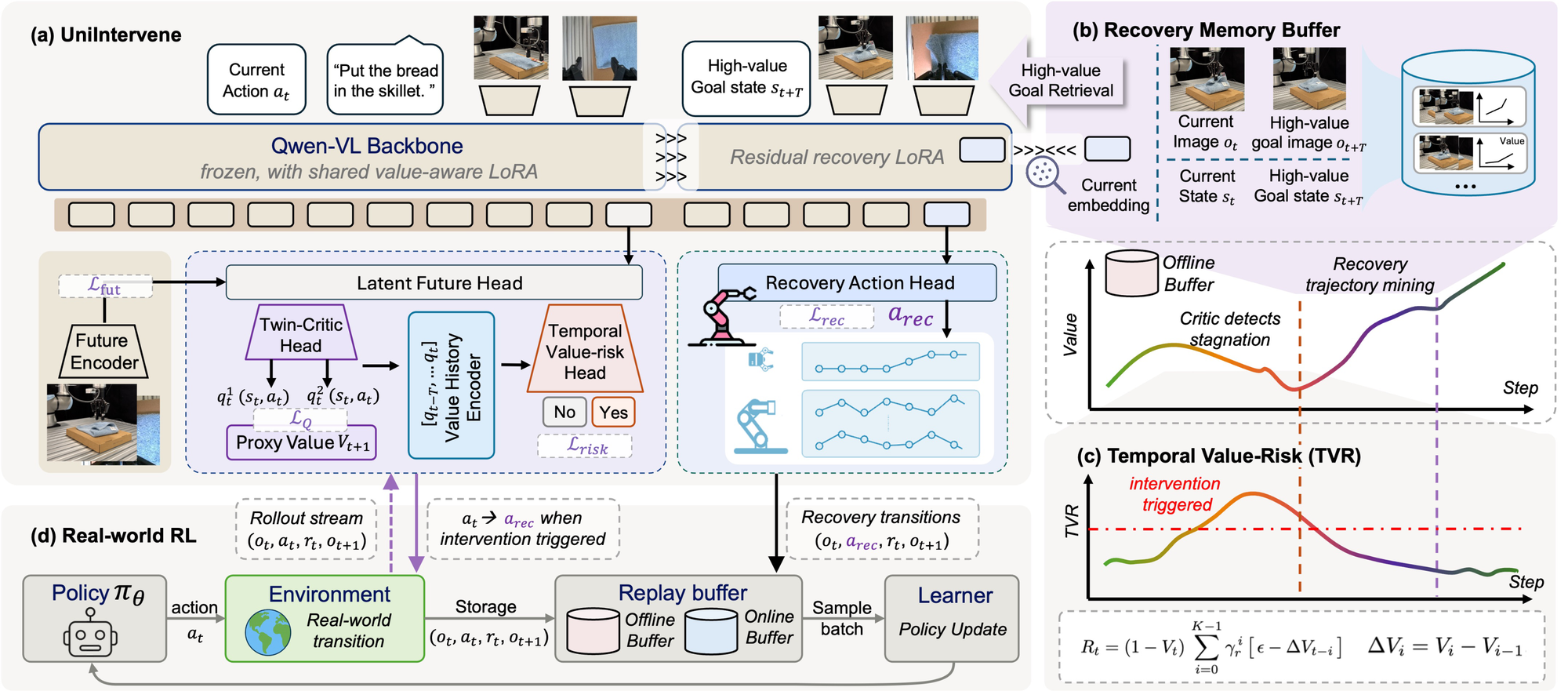
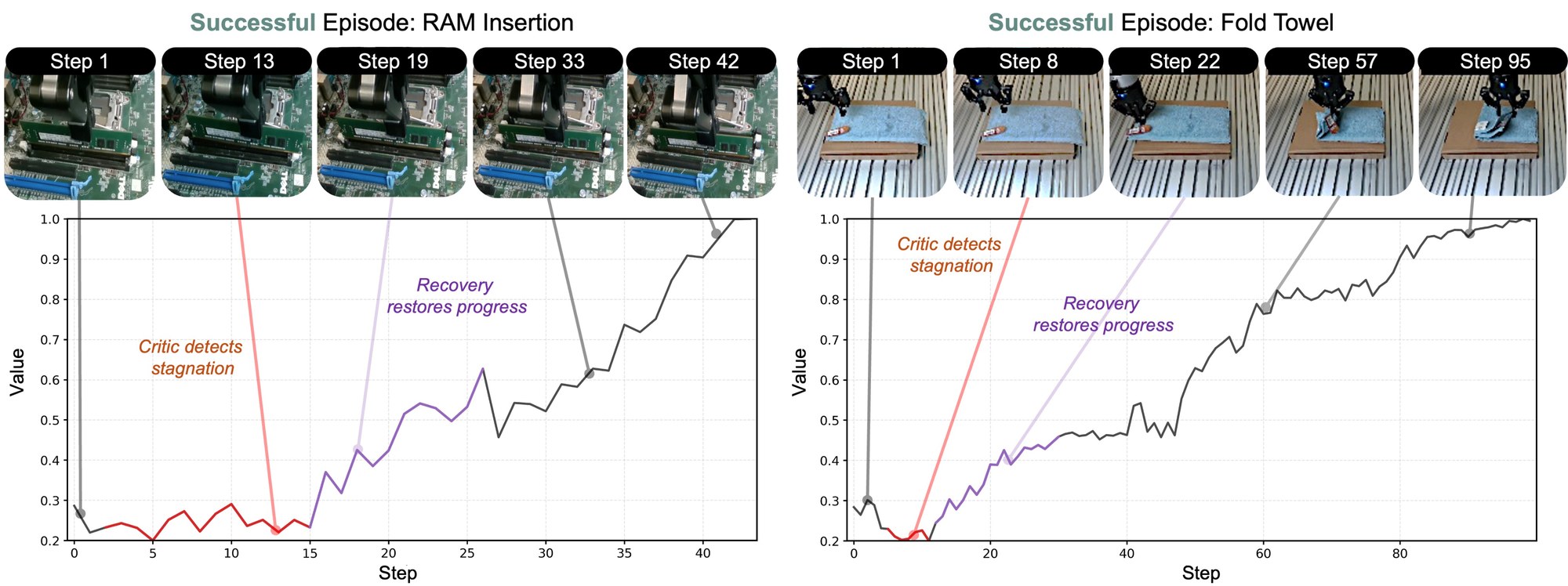
An agentic intervention model that detects unproductive exploration and autonomously recovers the policy toward high-value states — turning human intervention into a value-aware recovery process for real-world robot RL.
1Nanyang Technological University
2Beijing University of Posts and Telecommunications
✉ Corresponding author